|
■
Home ■ site map |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
BLOG: June 2010 - December 2013 II - Mammography 6. Screening X-ray mammography: Current picture
A s illustrated in more details on previous pages, what we know about benefits and risks of screening mammography, widely advertised as a big factor in the fight against breast cancer (BC), is undergoing major transformation. The decades-long low-risk/significant-benefit image is rapidly changing into the new, factual one, where it's uncertain whether the benefit is greater than harm.Since the pro-screening side still has overwhelming influence, their newly repackaged views promoting significant benefits and low risk of screening, based on questionable concepts and/or selective use of evidence and sources, keep colliding with and contradicting to the new set of research data that emerged within the past decade. This makes the big picture very confusing for the average woman, who has to decide who to believe when making her choice. And - to begin with - the matter is not exactly simple. The efficacy of screening can be assessed in more than one way, comparing: 1 - invited vs. uninvited population 2 - actually screened vs. uninvited population, or 3 - actually screened vs. actually unscreened population In all three cases, the control group can have either regular clinical breast examination, with or without practicing breast self exam, or have no screening at all. #1 is how the BC randomized controlled trials present their result, with the "invited population" here being the women assigned to screening, whether they actually do attend, or not. This is also what most researchers outside pro-screening camp considers appropriate for assessing efficacy of the actual screening programs. The difficulty here is not only that a relatively significant portion of the invited population does not attend screening regularly, or not at all, but also that a relatively significant portion of women from uninvited population can and does attend screening on opportunistic basis. If screening has any appreciable effect, positive or negative, it will be diminished by either one. So it can make screening appear less beneficial - or less harmful, depending on the nature of its effect. #2, comparing actually screened vs. uninvited population, seems more appropriate - and pro-screening advocates insist it is - but also has serious drawbacks. One is that it cannot be assumed, even within a randomized controlled trial, that the actually screened population is comparable to the control group as a whole. In fact, there is evidence that the sub-group of non-attendees in BC trials, for still unknown reasons, is likely to be a high-risk group of women (not only for getting breast cancer, but also for dying from it), that probably has a similar counterpart in the control group. The other drawback, which is quite obvious, is that the same standard would require filtering women that had opportunistic screening out of the uninvited population - a factor notoriously hard to control. Finally, #3, comparing actually screened vs. actually unscreened population would be the most appropriate for assessing the theoretical potential of screening, but... it is not viable in practice, not only due to the difficulty of determining who was actually screened, and how often, but even more in achieving that those two randomly formed groups are sufficiently comparable (it is known that women attending screening have generally higher level of education and living standard, healthier lifestyle and lower breast cancer mortality). In short, any assessment of screening efficacy is approximate due to inherent limitations. And that without even attempting to make it more individual, rather merely finding statistical parameters for (usually) four age groups. In other words, the efficacy of screening is shown for the average "statistical" woman in a certain age range - a fiction that can be very different from you. For instance, one of key parameters of screening efficacy - its sensitivity - can be as much as three times lower for women with very dense breasts, compared to the commonly cited figures. Your vulnerability to cardiovascular damage caused by unnecessary radiation treatment may be significantly higher than what the average figure is, and so on. To create a big picture of mammography screening efficacy at this point in time, we'll start with one of the very few research articles attempting to give unbiased, evidence-based view, constructing a nearly complete map to its benefits and harms (Promoting Screening Mammography: Insight or Uptake?, J.D. Keen, 2010). The author - a Chicago radiologist - starts with
these basic data points, per 1,000 U.S. women over 10-year
period (from Table 1 in the article):
The source for the figures in this table was SEER (Surveillance, Epidemiology and End Results), National Cancer Institute database, 2000-2006. They are in agreement with the graph showing U.S. BC incidence and mortality rates for the female population sub-groups, also based on SEER data. Next step is applying screening-specific figures to this basic data. Keen opts for the USPSTF as the main reference source (Screening for breast cancer: an update for the U.S. Preventive Services Task Force, Nelson et al. 2009), which gives BC mortality reduction of 15% and 30% for 40-59y and 60-69y age range, respectively, as well as 74%, 81% and 82% screening sensitivity for a decade of screening starting at 40, 50 and 60y of age respectively. Same reference also gives 68% for the average participation rate. Since USPSTF's take on overdiagnosis is clearly inadequate (estimated typical range 1-10%, based on very selective - read: biased - evidence), Keen opts for the 30% overdiagnosis figure from a recent Nordic Cochrane Center review (Screening for breast cancer with mammography, Gotzsche and Nielsen, 2009). This is still somewhat conservative figure since, as the author notes, the most recent sources place overdiagnosis rate at the 50% level. Applying the mortality reduction rate to the no-screen death rate from above table gives the "lives saved" figure. Note that the "life saved" term is not proper, since lowered BC mortality in the screening population does not necessarily imply lower overall mortality within it. Since research on all-cause mortality in screened vs. unscreened populations remains insufficient and inconclusive - with the few quality controlled trials indicating that it could be higher for the screened population - it cannot be assumed that lower BC mortality actually saves lives. For that reason, reduction in BC deaths in the screened vs. unscreened population will be hereafter termed for what it is: screening-averted BC death. Applying screening sensitivity times participation rate to the diagnosis rate figure from above table, gives the number of screen-detected cancers. And applying the overdiagnosis rate to the number of diagnosed BC gives the pseudo-disease figure (pseudo BC: diagnosed BC which would have never become symptomatic, either due to being indolent, slow growing in older women, or spontaneously regressing). The numbers that Keen arrived at are
presented in the following table, also per 1000 women over 10-year
period.
According to this database, not much more than half of all diagnosed BC is screen-detected, which puts a huge dent into the "early detection benefit" doctrine. Even worse, almost a half of those screen-detected BC are pseudo-disease, i.e. abnormal growth which never becomes symptomatic. Pseudo BCs are shown vs. screen-detected BC, not vs. all diagnosed breast cancers, because they are nearly entirely a product of the mammography screening. The overdiagnosis rate that they were calculated from - 30% over the number of actual cancers, both screen and off-screen detected, or 23% in the total of actual and pseudo BC - taken from Gotzsche and Nielsen, 2009, is conservative, since based on the analysis of large random controlled trials, which were (1) not designed to monitor for overdiagnosis, and (2) are not comparable to women at large with respect to screened population. Studies of the actual screening programs, comparing number of cancers in screened vs. unscreened population over extended periods of time, have found generally higher overdiagnosis rate, reaching more than 50% over the number of actual BC. In addition to overdiagnosis, Keen also includes other two significant drawbacks of screening, false negatives and false positives, the latter with the frequency of its most serious consequence - unnecessary biopsy. His data for these aspects of screening are also from the above cited USPSTF reference, which estimates the rate of biopsy varying from 1 in nearly 10 for 40-49y age, to 1 in nearly 7 for age 60-69. However, it is taken out of a 10-year context, since the USPSTF data is for a single round of screening, hence does not show the effect of accumulation over time. Is it necessary to keep all the aspects of screening in the same context, which is 10-year period, since screening normally takes place over an extended period of time? Numbers-wise, there is some difference between screening 10,000 women in a single screening round, and screening 1,000 women for 10 years annually. Data indicates that if the same group of women is screened over extended period of time, rates for these three mammography negatives - false positives, false negatives and biopsies - tend to decrease vs. first-time single screen round. If, for instance, a single-round false-negative rate is 1.3 in 1,000, there will be about 13 false negatives for 10,000 women screened once, and probably somewhat less for 1,000 women screened annually over 10 years. Unfortunately, there is not enough information to draw more specific conclusion, and in construing this big picture we'll only assume that these rates are probably somewhat reduced over extended time period. Significant difference between a one-time mass screening and a prolonged screening period is that in a single screening round with 10,000 women, every individual woman's risk of false-negative is 0.13%, while for 1,000 women over 10 years of annual screening it is much - although not ten times - higher: roughly around 1%. Or, in the more relevant context, if the BC detection rate is 5 in 1,000 (0.5%), a women with breast cancer has about 20% risk of having it missed at screening in a single round, while likely to have nearly two misses, statistically, over 10-year period of annual screening. Till recent, there were a very few reference sources with specific data on these screening negatives in the U.S.: the false positive rate, with the rate of related biopsies, and false negative rate. For the two of these three screening aspects - the rate of false positives and the related biopsies - it was pretty much limited to two U.S. studies. One that came up with the overall 49% false-positive rate after 10 mammograms, 39% of which had biopsy (Elmore et al. 1998, for 2400 women 40-69y of age). The other, with much larger number of women screened once (only the 1st screen with those screened more than once) within 1985-1997, had about 10% false positive rate, with 1.2% biopsy rate (Kerlikowske et al. 2000, for 389,533 women 30-69y of age; the 30-39y group is omitted from consideration here). Both studies have serious limitations: Elmore et al. had as many as 8,800 women excluded due to the lapse in enrolment in the HMO whose members were subject of the study. Since disproportionately large number of women could have quit health plan because of having false-positive, that would have lowered the actual figure. The unusually low false-positive rate in this study - less than 7% for the 40-69y age group at the 1st screen - as well as about the doubled standard rate of BC incidence (nearly 1% per screening round), suggest that this study could have had a significant sampling bias. In addition, 2400 women participants was a random sample from 4319 eligible women, making it even more uncertain that it was representative of the broad population. On the other hand, Kerlikowske et al. was limited to a single screen per women (the first recorded in a registry), and did not include fine needle biopsies. If we assume that fine needle biopsies were about half as frequent as core and surgical biopsies combined, this indicates biopsy rate of nearly 2% or, with 10% false-positive rate, 1 for every 5 false-positives. This is half the rate in Elmore et al. but more than twice the USPSTF estimate. Since Kerlikowske et al. used 6 registers from the same source as USPSTF - the National Cancer Institute Breast Cancer Surveillance Consortium (BCSC) - it probably had similar problem in assessing rate of biopsies as USPSTF. Evidently, these sources do not provide complete and/or reliable information. That only echoes the overall problem of screening mammography - lack of complete and/or reliable information on its basic aspects, despite decades of its widespread use. A more recent study, also based on the BCSC data, found nearly 10% false-positive rate or, similarly to the USPSTF, only about 1 biopsy (all types) for every 10 false positives (Rosenberg et al. 2006, 1.12 million women in the 1996-2002 period, nearly 2.5 screens per woman average). Probably the most most
reliable single piece of evidence here is the rate of benign
biopsies reported by - no surprise - the Canadian study (Canada
2, 50-59y age group). Here is the data for the for abnormal
mammograms, the resulting BC diagnosed, and benign biopsies from this exceptionally meticulous study:
*for the entire physical+mammogram group Unfortunately, only surgical benign biopsies are given for the mammography-only group (MO, the group where abnormal growth was detected by mammography alone). The number of needle biopsies is estimated from the surgical-to-needle biopsies proportion in the entire mammography+physical group. Since the surgical-to-needle ratio in the physical-exam-only group is generally somewhat lower (0.75 -0.93 range, 0.83), the ratio in mammography-only group is probably somewhat higher, and their actual total biopsies somewhat lower than the estimated figure. The ratio of abnormal screens for mammography vs. physical alone of 0.4 to 0.6 implies that the more appropriate surgical-to-needle biopsy ratio for mammography alone is 1.38, i.e. that about 60% of all biopsies were surgical, and 40% needle, either core or aspiration. If so, the total of benign biopsies within mammography-only group in the Canada-2 study was closer to 1520, and the ratio vs. false positives around 60%. Here's a brief summary for the general (40-69y age) biopsies-to-false-positives ratio for these available sources:
▪ USPSTF: about 8%, or 1 biopsy
for 12 false positives It is easy to discount the first two, both based on the BCSC data, not only because USPSTF itself indicates that the rate "may be underestimated". Having 11 out of 12 false positives ruled out as a possible BC without the need for biopsy of any type is simply not realistic. Kerlikowske et al. seems more believable, but its (estimated) number is still significantly behind Elmore et al. and Canada-2 trial. Allowing that the latter may not be representative of the U.S. screening programs, leaves Elmore et al. as the most reliable and complete source. None of these sources gives the rate of false negatives in the longer-term context, but we can assume that it does not change significantly relative to the rate of true positives. So, based on the few sources available, it can be approximated as 1 in 3, 1 in 4, and 1 in 5 vs. number of screen-detected BC, for the 40-49, 50-50 and 60-69y age group, respectively, based on the USPSTF reference (28% average for the three age groups from 40 to 69y, for single screening round). This is also in fair agreement with the overall rate of interval (i.e. not screen detected) BC being nearly 50%, about as much as the rate of false negatives within interval cancers, according to the Canadian trial.
So, here are the likely rates - at
least as rough approximations - of mammography screening outcomes
per 1,000 women screened (except where noted otherwise):
* Percent of false negatives in all tested
women with BC; derived from the sensitivity figure s(%)
as 100-s; Obviously, all these numbers are only averages, and some are very approximate, due to the lack of data, both, from research and from the actual screening programs. But this is pretty much the available information, and it is sufficient for constructing a big picture of women's chances to benefit from, or be harmed by mammography screening. Based on the above, here is
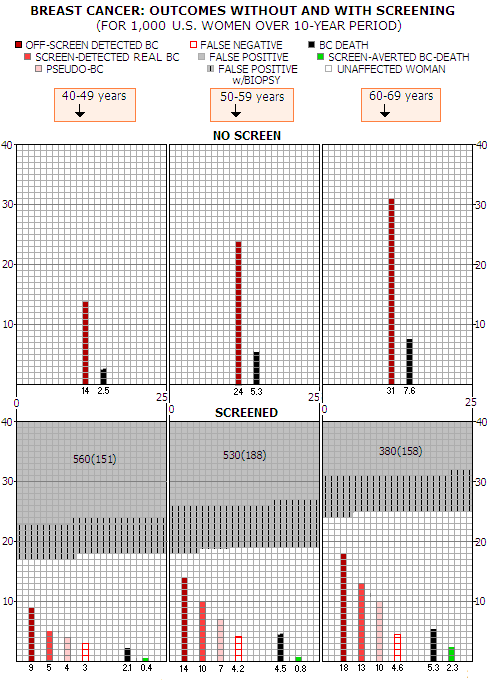
what the chances for a particular BC-related outcomes come to:
*No -screen group does not include screen-detected pseudo-BC There is more breast cancer cases in the screened population because they include screen-detected pseudo-BC, which would have never become symptomatic. Still, a woman with pseudo-BC that showed on her mammogram and was subsequently confirmed by inaccurate diagnosis as a real cancer, is being told that she does have BC, and is treated for it as if it is real. Screen-detected BCs are generally those that haven't become symptomatic yet, and represent the proportion of the early detection benefit. False negative tests are for BCs present at the screen but undetected; some of them are too small, but some are detectable and overlooked. These BC are detected either off-screen in the inter-screening interval (interval BC), on the following screen, or after the following screen (off-screen), in women who missed to show for it (incident BC). Thus most of them are contained within the off-screen and screen detected BC (except for those in the last year, or so), and do not add to the total of BCs in the screened population. They merely show the rate of BC missed by screening. This current picture of the risks and benefits of standard mammographic screening vs. no-screening is shown on graphs below. Each square represents a single women, 1,000 per age group altogether, and the outcomes shown for each age group are for 1,000 women, over 10-year period.
Note that screen detected real BC and pseudo BC add to the total of all screen-detected cancers. So, according to the best information available at this time, here is what the average woman faces when deciding whether to make screening mammography part of her life, or not. The area of each outcome vs. area of the entire 1000-square area represents the probability of that particular outcome to take place for the average (statistical) woman. The main points can be summed up as follows: ∙ for screened woman with a real BC, chances of having it detected by mammography screening are about 30%, 35% and 37% for 40-49y, 50-59y and 60-69y age group, respectively (given as screen-detected real BC vs. sum of real BC, off-screen detected BC, and false negatives) ∙ statistical gain in BC mortality reduction due to the screening is small enough to be uncertain in the 40-49y age group (a single BC death less requires more than 2500 women screened over 10 years); it is still small in the 50-59y age group (a single BC death less requires screening 1300 women for 10 years), and only becomes relatively significant in the 60-69y age group (single BC death less for 435 women screened over 10 years) ∙ price to pay for the tiny, statistically questionable BC mortality reduction in the 40-49y group is huge: over 10-year period, roughly every other women will have false positive test, and more than a quarter of them will have biopsy; at the same time, woman's chances of having BC detected off-screen, or to have it missed by screening, combined, are more than twice higher than those of having it detected by screening; in addition, her chances of being diagnosed with pseudo BC - i.e. abnormal growth that would have never become symptomatic - are nearly as high as having real BC detected by screening ∙ screening negatives are not significantly lower in the 50-59y age group, but do measure against the doubled (still low) statistical BC mortality reduction; only in the 60-69y group the rates of false positives and false negatives decrease significantly while, at the same time, BC mortality reduction becomes significant Key question, to which there is no clear answer yet, is whether BC mortality reduction in the screened population translates in the net (all-cause) mortality reduction. The main reason for this being still unknown is that it is exceedingly difficult to have the two populations - screened and unscreened - made comparable in terms of all-cause mortality. It is complex enough - and still not necessarily sufficiently successful - trying to make them comparable with respect to the risk of getting breast cancer, and dying from it, alone. Throwing into the mix other death causes - even only those major ones - makes it nearly impossible. And without knowing what is the effect on all-cause mortality, we simply don't know whether screening actually adds to life, doesn't, or, possibly, takes away from it. Breast cancer randomized controlled trials (RCT), in general, are not designed to study all-cause mortality. They are also underpowered (i.e. with insufficient number of participants) for such task. Still, there are at least two reasons to look at their numbers: (1) they are the only place to find any information, and (2) the presence of a consistent pattern there would make it probable that it reflects the actual effect of screening on all-cause mortality. The trials' rate of reduction in BC mortality for the screened population does not add up with the all-cause mortality: the latter is reduced nearly twice more than what would result from fewer BC deaths alone. Even if the numbers would agree, that would have to be assumed accidental, considering the limitations of trial designs, and the absence of a clear trend. Individual trials are inconsistent, with four of them reporting either no change in overall mortality, or its increase for the screened vs. unscreened population; the other four report lower overall mortality for the screened population. We could say that we don't know what is the net effect of mammography screening on all-cause mortality. But it is, actually, more worrisome. If we, instead of representing breast cancer RCTs' all-cause mortality numbers in the usual statistical way, as weighted averages of mortality rates, simply add up all-cause deaths within the total population from all the trials combined, the risk ratio for dying of any cause is 26% higher for the screened population. In other words, for every four any-cause deaths in the unscreened population, there was five any-cause deaths in the screened population. This may not be statistically orthodox approach, but it is most directly based on the actual data. Considering other possible, or probable causes for higher all-cause mortality in the screened populations, such outcome is not only possible - it is the more likely one. Where would that leave us? The only remaining reason for mammography screening, at present, is that it seems to be reducing breast cancer mortality - and even that is marginal. If it turns out that this fairly uncertain small benefit is more than offset by the higher all-cause mortality - in addition to already recognized negatives and risks of screening mammography: false positives and negatives, overdiagnosis, overtreatment and screen radiation - that would have not only make it sink, but also sink fast. That's why it is not likely to happen. We have a big picture of the usefulness of mammography screening shaping up already. But lets take a closer look at its positives and negatives. YOUR BODY ┆ HEALTH RECIPE ┆ NUTRITION ┆ TOXINS ┆ SYMPTOMS |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||